Indexed Merkle Tree
We're implementing an "Indexed Merkle Tree" for efficient non-membership proofs, which we'll need for our Nullifiers Tree.
Here’s the paper with the idea: https://eprint.iacr.org/2021/1263.pdf
An indexed Merkle tree is a variant of the basic Merkle tree where the leaf structure changes slightly. Each leaf in the indexed Merkle tree not only stores some value but also points to the leaf with the next highest value:
where is the index of the leaf with the next higher value . By design, we assume that there are no leaves in the tree with a value between the range . The highest-valued leaf points at , by convension.
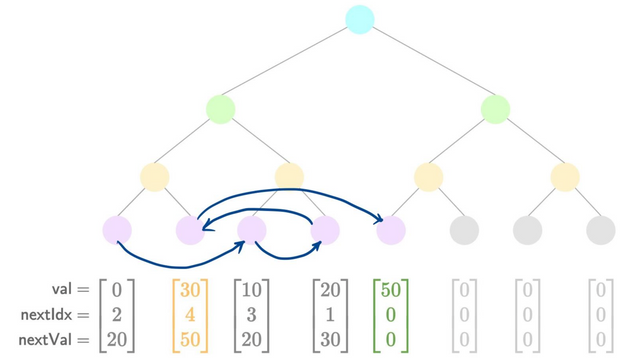
Let us look at a toy example of nullifier insertions in an indexed Merkle tree of depth 3.
- Initial state
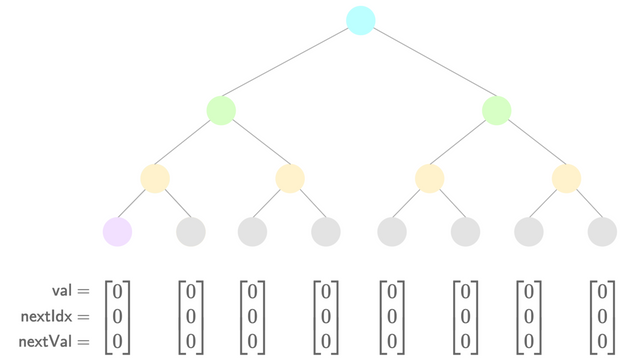
- Add a new value
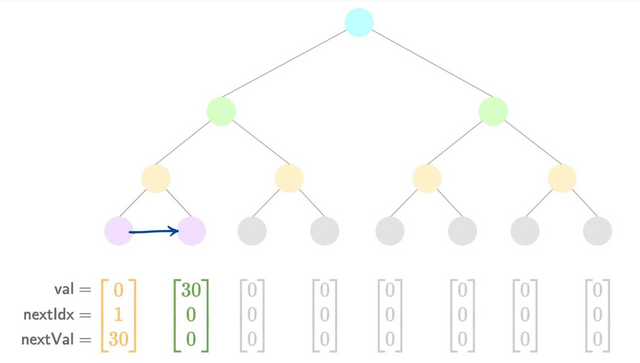
- Add a new value
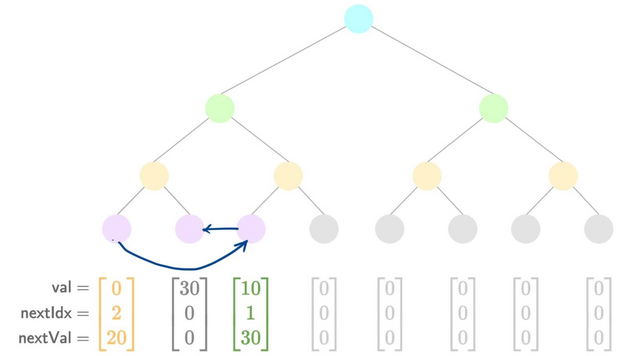
- Add a new value
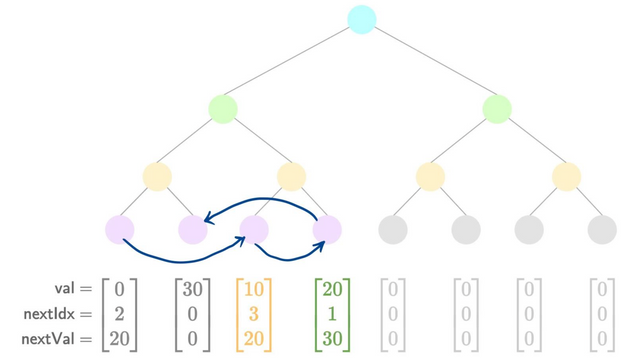
- Add a new value
Analysis - Constraint counts
Insertion
- Hash the old leaf:
oldLeaf = h(0, 0, 0)(for example). - Prove the old leaf existed in the tree:
nhashes. - Check the new leaf belongs in the slot it's being inserted into:
2range checks.- If (
oldLeaf.nextInd == 0):- Special case, we're inserting at the very end, so the new leaf must be the highest-valued so far.
assert(oldLeaf.val < newLeaf.val)
- Else:
assert(oldLeaf.val < newLeaf.val)assert(oldLeaf.nextVal > newLeaf.val)
- If (
- Copy over the old leaf's
nextvalues to the new leaf:assert(oldLeaf.nextInd == newLeaf.nextInd)assert(oldLeaf.nextVal == newLeaf.nextVal)
- Update the old leaf to point to the new leaf:
updatedLeaf = h(0, 30, 1).assert(updatedLeaf.nextInd == newLeaf.ind)assert(updatedLeaf.nextVal == newLeaf.val)
- Replace the
updatedLeafin the tree:nhashes. - Hash the new leaf:
newLeaf = h(30, 0, 0). - Add the
newLeafto the tree:nhashes.
Number of insertion constraints, in total:
3nhashes of 2 field elements (wherenis the height of the tree).3hashes of 3 field elements.2range checks.- A handful of equality constraints.
Non-membership proof
Suppose we want to show that the value 20 doesn't exist in the tree. We just reveal the leaf which 'steps over' 20. I.e. the leaf whose value is less than 20, but whose nextVal is greater than 20. Call this leaf the loLeaf.
- hash the low leaf:
loLeaf = h(10, 1, 30). - Prove the low leaf exists in the tree:
nhashes. - Check the non leaf 'would have' belonged in the range given by the low leaf:
2range checks.- If (
loLeaf.nextInd == 0):- Special case, the low leaf is at the very end, so the non leaf must be higher than all values in the tree:
assert(loLeaf.val < nonLeaf.val)
- Else:
assert(loLeaf.val < nonLeaf.val)assert(loLeaf.nextVal > nonLeaf.val)
- If (
Number of non-membership proof constraints, in total:
nhashes of 2 field elements (wherenis the height of the tree).1hash of 3 field elements.2range checks.- A handful of equality constraints.
Doing a non-membership check, then an insertion of that value
We combine the logic of the above two sections, where oldLeaf is renamed to loLeaf throughout, and nonLeaf is renamed to newLeaf. We can actually make some savings.
- Hash the low leaf.
- Prove the low leaf exists in the tree:
nhashes. - Check the new leaf 'would have' belonged in the range given by the low leaf:
2range checks.- If (
loLeaf.nextInd == 0):- Special case, the low leaf is at the very end, so the non leaf must be higher than all values in the tree:
assert(loLeaf.val < newLeaf.val)
- Else:
assert(loLeaf.val < newLeaf.val)assert(loLeaf.nextVal > newLeaf.val)
- If (
- Copy over the old leaf's
nextvalues to the new leaf:assert(oldLeaf.nextInd == newLeaf.nextInd)assert(oldLeaf.nextVal == newLeaf.nextVal)
- Update the old leaf to point to the new leaf, to create
updatedLeaf.assert(updatedLeaf.nextInd == newLeaf.ind)assert(updatedLeaf.nextVal == newLeaf.val)
- Replace the
updatedLeafin the tree:nhashes. - Hash the new leaf.
- Add the
newLeafto the tree:nhashes.
Number of constraints, in total:
3nhashes of 2 field elements (wherenis the height of the tree).3hashes of 3 field elements.2range checks.- A handful of equality constraints.
Batch insertion!
With this new indexed nullifier tree, we can perform batch insertions, which saves on the number of hashes required. We can't batch the checking or updating of the 'pointer' leaves, but we can batch the insertion of brand-new leaves, by inserting them as a little subtree at the next available positions in the tree (from left to right).
Number of constraints, in total:
Suppose we want to insert b leaves (assuming insertion of a neat power of 2, to make this illustrative maths simpler):
2nbhashes of 2 field elements (wherenis the height of the tree), to check and update the pointer leaves.(b - 1) + (n - log_2(b) + 1) = n + b - log_2(b)hashes of 2 field elements (to insert the new leaves as a batch).3bhashes of 3 field elements.2brange checks.bx "A handful of equality constraints".
Benefits
We can compare this kind of tree to a sparse merkle tree of height 254 (as was used in the old Aztec Connect system).
Previous nullifier tree depth: 254.
To update one leaf in the old, sparse nullifier tree, we needed to verify two membership proofs:
- that the old leaf value for the given nullifier was 0 (i.e. it's unspent); and
- that the updated leaf value for the given nullifier is 1 (marking it as spent).
Number of constraints using the old sparse nullifier tree, in total:
2 * 254 = 508hashes of 2 field elements.- A handful of equality constraints
Concrete comparison
Ignoring range checks, and overestimating that hashing of 3 field elements approximates to 2 hashes of 2 field elements, the approximate difference between batch insertion of a 254-heigh tree, versus an n heigh tree is:
508b - [2nb + (n + b - log_2(b)) + 6b] hashes of 2 field elements, minus 2b range checks.
Simplified: 501b - 2nb - n + log_2(b).
Suppose we choose a nullifier tree height of n = 45, for Aztec, and an illustrative nullifier batch size of b = 2048. Then the approximate saving is:
841,694 hashes (minus 4096 range checks).
1,040,384 hashes under the old approach, versus 198,690 (plus 4096 range checks). Roughly a 5x saving.
Participate
Keep up with the latest discussion and join the conversation in the Aztec forum.